رویکردهای مختلفی برای بازشناسی گفتار وجود دارد که موفقترین آنها رویکرد مبتنی تشخیص الگو است و تقریباً تمامی سیستمهای موفق امروزی بر اساس آن عمل میکنند. در این رویکرد گفتار به کمک تعدادی واحد آوایی (مانند کلمه ، هجا ، سه واجی یا واج) مدل میشود و برای بازشناسی نیز از تشخیص این واحدها و کنار هم قرار دادن آنها، متن متناسب با گفتار تشخیص داده میشود. در شکل 1 ساختار مرسوم برای یک سیستم بازشناسی گفتار (با رویکرد تشخیص الگو) نشان داده شده است. سیستمهای بازشناسی گفتاری که از این رویکرد استفاده میکنند، دارای دو فاز آموزش و آزمون میباشند.
در فاز آموزش الگوهای مربوط به هرکلاس که همان واحدهای آوایی هستند، با استفاده از روشهایی مدلسازی میشوند. مقایسه گفتار ورودی با الگوهای آموزش داده شده جهت تشخیص واحدهای آوایی موجود درگفتار ورودی، در فاز آزمون انجام میگردد. همانگونه که در این شکل نشان داده شده است، یک سیستم بازشناسی گفتار شامل دو جزء اصلی استخراج ویژگیها و واحد مدل کردن (برای فاز آموزش) و به کارگیری مدل یا جستجو (برای فاز آزمون و استفاده) میباشد. در این ساختار هر کدام از واحدهای مربوطه نیز خود به روشهای مختلفی قابل انجام هستند. واحد استخراج ویژگی که گاهی آن را پیشپردازش نیز میگویند، یکی از واحدهای مورد نیاز اغلب کاربردهای بازشناسی الگو میباشد. هدف این واحد در سیستمهای بازشناسی گفتار کاهش حجم محاسبات و حذف افزونگیهای موجود در سیگنال گفتار با استخراج تعداد محدودی پارامتر از آن است. پارامترهای استخراج شده توسط این واحد بایستی متناسب با کاربرد مورد نظر باشد به این معنی که برای کاربرد بازشناسی گفتار مستقل از گوینده سعی شود پارامترهایی استخراج شود که حداقل حساسیت را به نحوه ادای آواهای مختلف یک گفتار خاص از نظر کلام و گوینده داشته باشند. از طرفی برای کاربردهای وابسته به گوینده مانند تشخیص هویت گوینده به کمک گفتار بهتر است واحد استخراج ویژگی پارامترهای وابسته به گوینده مانند وابستگی به لحن، شکل و طول مسیر صوتی ، طول گام و غیره را استخراج نماید. از آنجا که کلیه عملیات بعدی روی این ویژگیها انجام میشود، بکارگیری یک روش توانا از عوامل موفقیت یک سیستم بازشناسی خواهد بود. با استفاده از روشهای استخراج ویژگی سیگنال به پارامترهایی که آنها را بردارویژگی مینامند تبدیل میشوند و کلاسهبندی روی این پارامترها صورت میگیرد. پارامترهای مورد استفاده عمدتاً از طیف کوتاه و پنجره بندی شده سیگنال گفتار که همان فریمها یا قابها هستند، بدست میآیند. روشهای مختلفی برای استخراج ویژگی وجود دارند که برخی از ایده تولید گفتار در سیستم صوتی انسان و برخی دیگر از ایده سیستم شنوایی بهره میگیرند. از میان روشهای مختلف برای استخراج ویژگی، دو روش آنالیز پیشگویی خطی (PLP) و ضرایب کپسترال فرکانسی در مقیاس مل (MFCC) به نسبت سایر روشها موفقتر و پرکاربردتر هستند.
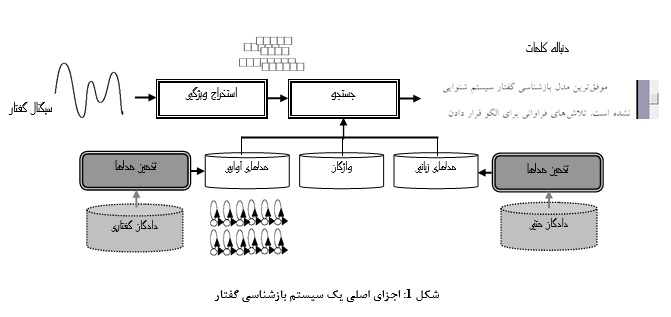
در فاز آموزش معمولاً دو نوع مدل آماده میشود که در فاز آزمون از آنها استفاده شود، مدلهای آوایی و مدلهای زبانی . استخراج مدلهای آوایی از روی دادگان گفتاری و با استفاده از روشهای مختلفی امکانپذیر است که از مهمترین آنها میتوان روشهای مدل انطباق زمانی پویا یا DTW (که در گوشیهای تلفن همراه برای شمارهگیری صوتی با بیان نام فرد به کار میرود)، شبکة عصبی مصنوعی (ANN) و مدل مخفی مارکوف (HMM) را نام برد. از میان این روشها، مدل مخفی مارکوف به نسبت سایرین موفقتر عمل کرده و عمده سیستمهای کاربردی امروزی از آن استفاده مینمایند. به علاوه ترکیب روشهای فوق نیز در برخی از سیستمها استفاده شده است. مدلهای زبانی معمول مورد استفاده در سیستمهای تشخیص گفتار امروزی شامل روشهای گرامری و آماری هستند. در روش گرامری سعی میشود که به جملات خروجی ساختار گرامری آن زبان (یا آن کاربرد خاص) اعمال شود و در روش آماری احتمال پشت سرهم آمدن کلمات (مثل مونوگرام یا احتمال وقوع کلمات در زبان، بایگرام یا آمار وقوع دو کلمه پشت سر هم در زبان و ...) به عنوان مدلهای زبانی استخراج شده و مورد استفاده قرار میگیرند. واژگان نیز از اجزای اصلی مورد استفاده در سیستمهای بازشناسی گفتار هستند که شامل لیست کلماتی است که توسط سیستم بازشناسی میگردند. در واژگانهای مورد استفاده در سیستمهای بازشناسی گفتار پیوسته با تعداد واژگان زیاد، علاوه بر لیست خود کلمات، اطلاعات مختلفی در مورد هر کلمه مانند احتمال وقوع آن در زبان، احتمال وقوع آن بعد از سایر کلمات، نقش (های) گرامری در جمله و ... را نیز شامل میشود. به این گونه واژگانها، واژگان محاسباتی گفته میشود.
بعد از آموزش مدلها و هنگام آزمون یا استفاده، بایستی از روی ویژگیهای سیگنال، دنبالهای از آواهای مرتبط تشخیص داده شود و سپس باید برای دنباله آوایی پیدا شده بهترین دنباله کلمات مرتبط را پیدا کرد. به این فرایند جستجو گفته میشود. در یک سیستم بازشناسی گفتار پیوسته، با در اختیار داشتن مدلهای آکوستیک واحدهای آوایی، یافتن واحدهای آوایی گفتار ورودی به یك مسألة جستجو تبدیل میشود، به طوری كه بهترین انطباق ممكن بین دنباله آوایی سیگنال ورودی و مدلهای آکوستیک ایجاد شود. در هنگام جستجو، احتمال تعلق یا میزان شباهت بردارهای ویژگی گفتار ورودی، با مدلهای مربوط به واحدهای آوایی، محاسبه شده و از میان محتملترین جوابها دنبالههایی از واحدهای آوایی به عنوان فرضیه شکل میگیرد. فرضیهای كه بیشترین امتیاز را داشته باشد، بهترین جواب خواهد بود. در یك جستجوی كامل كه همة فرضیههای ممکن مورد بررسی قرار میگیرند، تعداد فرضیهها با افزایش تعداد بردارهای ویژگی گفتار ورودی، به طور نمایی افزایش پیدا میكند، ار اینرو معمولاً از روشهای جستجویی استفاده میشود که قادرند به جای بررسی کل فضای جستجو، تنها با بررسی قسمتی از فضای جستجو، جواب خوبی بدهند. در بازشناسی گفتار پیوسته، روشهای مختلفی برای جستجو وجود دارد. مشهورترین روشهای جستجو عبارتند از: جستجوی ویتربی که بر مبنای الگوریتم ویتربی عمل میکند، جستجوی ویتربی شعاعی که شکل کاراتری از جستجوی ویتربی است و جستجو بر مبنای پشته که بر مبنای الگوریتم جستجویA* عمل میکند. در سیستمهای با واژگان بزرگ و سیستمهایی که واحد آوایی آنها واحدهایی کوچک مثل واج یا هجا هستند، بایستی دنباله آنها به دنباله کلمات تبدیل شود. از آنجایی که خروجی رمزگشای آکوستیک، دنبالهای ناقص و خطادار از واجها میباشد، برای تبدیل دنبالة واجی به دنبالة کلمات، نیاز به یک مدل زبانی و یک رمزگشای زبانی داریم. در تبدیل دنبالة واجی به کلمات میتوان از دو رویکرد استفاده کرد. در حالت اول دنبالة واجی حاصل از رمزگشای آکوستیکی به طور کامل تشکیل میشود، سپس با استفاده از در خت واژگان و الگوریتمهای جستجوی گراف، بهترین دنبالة کلمات متناظر با دنبالة واجی تشکیل میگردد. در ریکرد دوم، همزمان با شکلگیری دنبالة واجی، بهترین دنبالة کلمه نیز با جستجو در یک درخت واژگان به دست میآید. استفاده از اطلاعات بیشتر زبانی مانند اطلاعات آماری سطح بالاتر و استفاده از گرامر میتواند نتایج بهتری را منجر شود. این اطلاعات میتواند هم روی دنباله کلمات نهایی برای امتیاز دهی مجدد فرضیهها استفاده شود و هم در حین ایجاد دنباله کلمات از روی دنباله واجی جهت جلوگیری از رشد فرضیههای نادرست و ضعیف بکار گرفته شود.
در آزمودن یک سیستم بازشناسی گفتار، ممکن است یکی از سه نوع خطای حذف ، درج و جایگزینی اتفاق بیافتد. خطای حذف زمانی اتفاق میافتد كه یك واحد آوایی (کلمه یا واج) در سیگنال گفتار وجود دارد ولی بازشناسی نمیشود. درخطای درج، واحد آوایی بازشناسی شده در سیگنال گفتار وجود ندارد. این نوع خطا معمولا در هنگام تشخیص نویز به جای یک واحد آوایی پیش میآید. وقتی كه یك واحد آوایی به اشتباه به جای یک واحد آوایی دیگری بازشناسی میشود، خطای جایگزینی رخ داده است. با توجه به این خطاها، برای ارزیابی عملکرد سیستمهای بازشناسی گفتار از چند معیار كارایی می توان استفاده کرد که دقت و یا به طور معادل نرخ خطای کلمات رایجترین آنهاست. دقت بازشناسی معادل درصد تعداد کلماتی (برای واحد آوایی کلمه) است که سیستم بازشناسی آنها به درستی تشخیص داده است.






